DragonFly kernel List (threaded) for 2012-08
[
Date Prev][
Date Next]
[
Thread Prev][
Thread Next]
[
Date Index][
Thread Index]
GSoC: Add SMT/HT awareness to DragonFlyBSD scheduler
Hello,
In the following lines I will make a brief description of my work during
GSoC:
- I developed a mechanism to discover the CPU topology. All the information
about cpu_topology is obtained using "sysctl hw.cpu_topology". You can see
different topologies in [1][2][3].
- I added a SMT heuristic, so that the bsd4 scheduler to take the free
physical cores, and then start with the second hyper-thread of each core.
Here I added one more rule: if all physical cores are taken, schedule on the
hyper-thread that has the most interactive sibling (the less batchy). To
enable/disable this option use "kern.usched_bsd4.smt" (0 - disable, 1 -
enable; if no HT available then you won't be able to configure this - it
will notice you the is not supported). You can see some meaningul results at
[4]. Its a dual-xeon with 12 cores/24 threads. There were run 12 processes
(so to fairly ocupy all the cores). As you can see, the results are more
constant.
- I added a cache_coherent heuristic (make use of the hot-caches). This
option tries to schedule a CPU-bound process (batchy relative to the other
running processes) to the last cpu that had run. "the last cpu" can be
configured to be the thread/core/socket/any (any is the same as the original
scheduler). This option can be enabled/disabled using "sysctl
kern.usched_bsd4.cache_coherent". Also there are other configurable
parameters for this heuristic:
-- "kern.usched_bsd4.upri_affinity: 16" (defines the minimum distance in
number of PPQs to decide if a process is batchy or not, relative of current
running processes. 16 is default); PPQ is for priorities-per-queue, so when
we say 16 PPQs basicly it meens that the processes are at a distance of 16
queues (in other words: they are in two different priority queues and
the distance
between them is 16). Also you might want to know that there are 32 queues
in the bsd4 scheduler.
-- "kern.usched_bsd4.queue_checks: 5" (the number of processes to check on a
queue when trying to find a suitable one [that had its home on the current
CPU]. We don't want to search for too long because we are in a locked area);
-- "kern.usched_bsd4.stick_to_level" (defines the level you want the scheduler
to stick a process to; one can see the available options using "sysctl
hw.cpu_topology.level_description").
e.g.
xeon28# sysctl kern.usched_bsd4.smt=0 /* disable SMT */
kern.usched_bsd4.smt: 1 -> 0
xeon28# sysctl kern.usched_bsd4.smt=1 /* enable SMT */
kern.usched_bsd4.smt: 0 -> 1
xeon28# sysctl kern.usched_bsd4.cache_coherent=1 /* enable cache coherent*/
kern.usched_bsd4.cache_coherent: 1 -> 1
xeon28# sysctl hw.cpu_topology.level_description /* view level description */
hw.cpu_topology.level_description: 0 - thread; 1 - core; 2 - socket; 3
- anything
xeon28# sysctl kern.usched_bsd4.stick_to_level=2 /* stick to the socket */
kern.usched_bsd4.stick_to_level: 0 -> 2
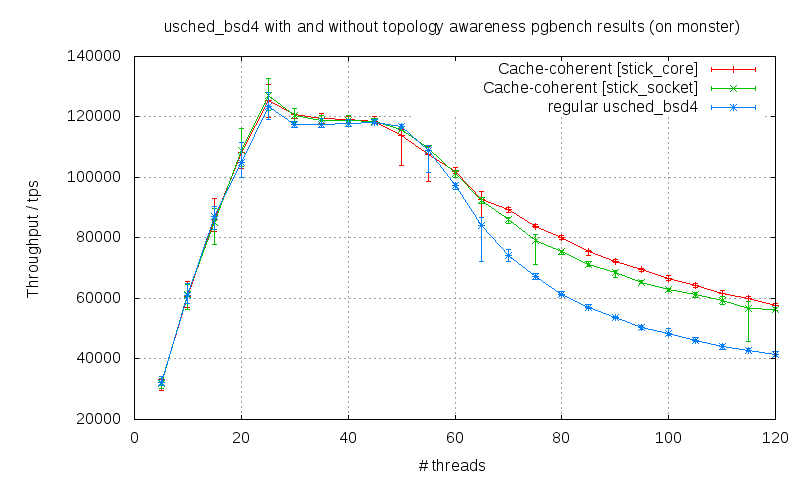
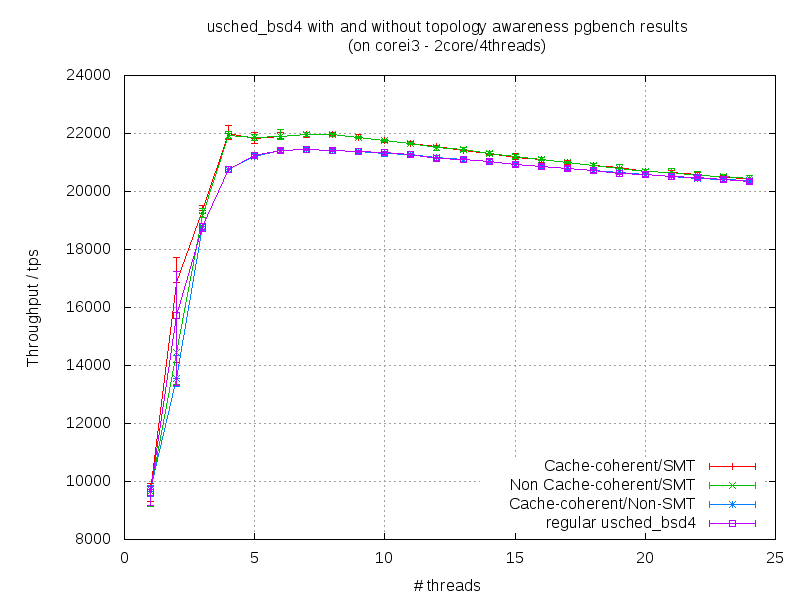
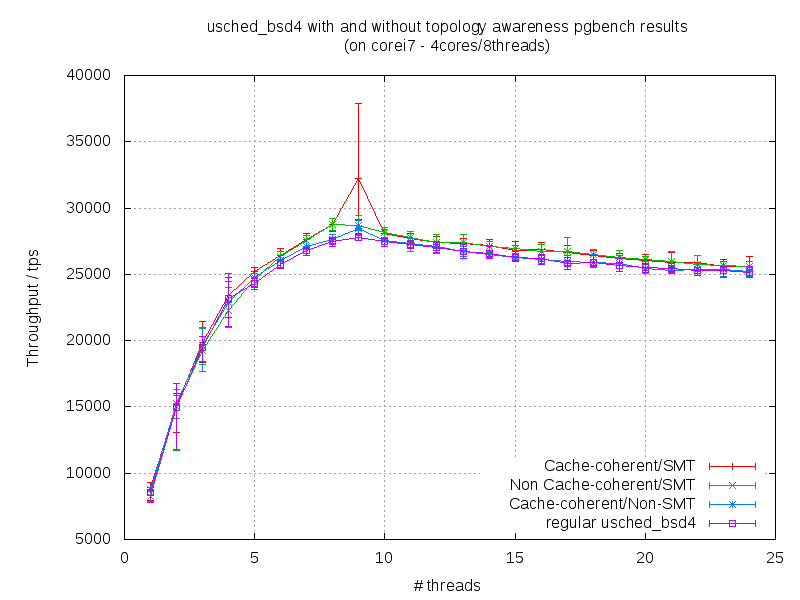
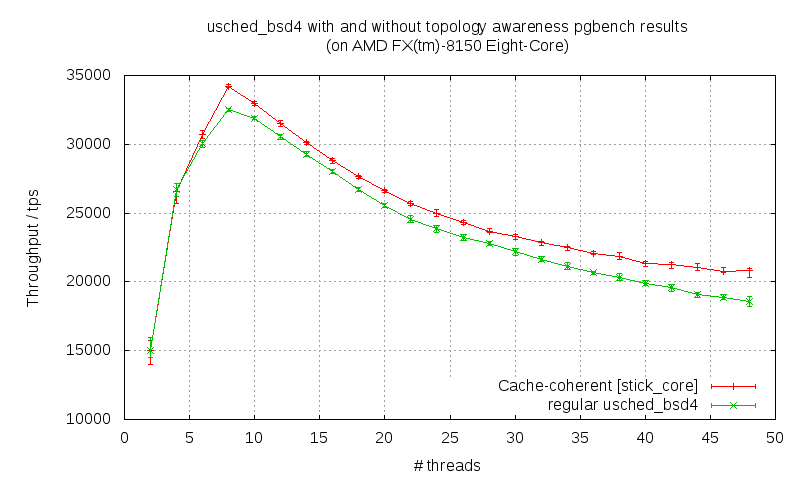
This last option (cache coherent) was tested on various platforms. I made graphs
with all my results using gnuplot. The general plots directory is at
[0]. A brief
description: monster on sysbench [5] and pgbench [6] (comparison between
cache_coherent stick to the core vs. stick to the socket vs. original
scheduler);
core i3 pgbench [7] (comparison between cache coherent/smt vs non-cache
coherent/smt vs cache coherent/non-smt vs original scheduler), core i7 same
as core i3 [8], dual-xeon with 12cores/24threads same as corei3 [9] and same
as monster at [10], amd buldozer with 8 cores [11].
As you can see, the results are getting better on AMD (monster and buldozer)
when the number of threads is getting higher then the number of cpus because
the context switches are increasing and when the process is reschedule, it can
take advantage of the hot cache of its home cpu.
On intel machines, the perfomances are getting better when the number of
threads+clients is doubled in comparison with the total number of cpus
(there is a portion in the plots where you can see the obvious difference).
On the corei3/corei7 may be is because of the small caches. On the dual-xeon
the L3 cache is big enough (12MB/socket) but probably is too slow and there
is no gain if we stick a process to the socket.
I would like to thank to Alex for his help and support in all I have done.
Also thanks to Matthew for clarifying me with the flow of the scheduler and
the acces on monster, ftigeot and profmakx for the access on their machines.
I hope I didn't forget anybody:D.
[0] http://leaf.dragonflybsd.org/~mihaic/plots
[1] http://leaf.dragonflybsd.org/~mihaic/dual_xeon_cpu_topology.out
[2] http://leaf.dragonflybsd.org/~mihaic/core-i3_cpu_topology.out
[3] http://leaf.dragonflybsd.org/~mihaic/monster_cpu_topology.out
[4] http://leaf.dragonflybsd.org/~mihaic/openssl_smt_bench.out
[5] http://leaf.dragonflybsd.org/~mihaic/plots/sysbench-monster/topo.png
[6] http://leaf.dragonflybsd.org/~mihaic/plots/pgbench-monster/topo.png
[7] http://leaf.dragonflybsd.org/~mihaic/plots/pgbench-corei3/topo.png
[8] http://leaf.dragonflybsd.org/~mihaic/plots/pgbench-corei7/topo.png
[9] http://leaf.dragonflybsd.org/~mihaic/plots/pgbench-dual_xeon_ht/topo.png
[10] http://leaf.dragonflybsd.org/~mihaic/plots/pgbench-dual_xeon_cc/topo.png
[11] http://leaf.dragonflybsd.org/~mihaic/plots/pgbench-buldozer/topo.png
[
Date Prev][
Date Next]
[
Thread Prev][
Thread Next]
[
Date Index][
Thread Index]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}