performance
Please note: Many of the figures on this page utilize SVG, if your browser does not show these a plugin needs to be installed or your browser updated.
DragonFly BSD has numerous attributes that make it compare favorably to other operating systems under a great diversity of workloads. Some select benchmarks that represent the general performance attributes of DragonFly are included in this page. If you have a DragonFly BSD performance success story, the developers would like to hear about it on the mailing lists!
Symmetric Multi-Processor Scaling (2012)
It is true that one of the original goals of the DragonFly BSD project was performance-oriented, the project sought to do SMP in more straightforward, composable, understandable and algorithmically superior ways to the work being done in other operating system kernels. The results of this process have become staggeringly obvious with the 3.0 and 3.2 releases of DragonFly, which saw a significant amount of polishing and general scalability work, and the culmination of which can be seen in the following graph.
The following graph charts the performance of the PostgreSQL 9.3 development version as of late June 2012 on DragonFly BSD 3.0 and 3.2, FreeBSD 9.1, NetBSD 6.0 and Scientific Linux 6.2 running Linux kernel version 2.6.32. The tests were performed using system defaults on each platform with pgbench as the test client with a scaling factor of 800. The test system in question was a dual-socket Intel Xeon X5650 with 24GB RAM.
NetBSD 6.0 was unable to complete the benchmark run.
In this particular test, which other operating systems have often utilized to show how well they scale, you can see the immense improvement in scalability of DragonFly BSD 3.2. PostgreSQL's scalability in 3.2 far surpasses other BSD-derived codebases and is roughly on par with the Linux kernel (which has been the object of expensive, multi-year optimization efforts). DragonFly performs better than Linux at lower concurrencies and the small performance hit at high client counts was given up willingly to ensure that we maintain acceptable interactivity even at extremely high throughput levels.
Note: single-host pgbench runs like the ones above are not directly useful for estimating PostgreSQL scaling behavior. For example, any real-world setup that needs to handle that many transactions would be using multiple PostgreSQL servers and the client themselves would be running on a set of different hosts. This would be much less demanding of the underlying OS. If you plan to use PostgreSQL on DragonFly and are targeting high-throughput, we encourage you to do your own testing and would appreciate any reports of inadequate performance. That said, the above workload does demonstrate the effect of algorithmic improvements that have been incorporated into the 3.2 kernel and should positively affect many real-world setups (not just PostgreSQL ones).
Swapcache
One of the novel features in DragonFly that is able to boost the throughput of a large number of workloads is called swapcache. Swapcache gives the kernel the ability to retire cached pages to one or more interleaved swap devices, usually using commodity solid state disks. By caching filesystem metadata, data or both on an SSD the performance of many read-centric workloads is improved and worst case performance is kept well bounded.
The following chart depicts relative performance of a system with and without swapcache. The application being tested is a PostgreSQL database under a read-only workload, with varying database sizes ranging from smaller than the total ram in the system to double the size of total available memory.
As you can plainly see, performance with swapcache is more than just well bounded, it is dramatically improved. Similar gains can be seen in many other scenarios. As with all benchmarks, the above numbers are indicative only of the specific test performed and to get a true sense of whether or not it will be a benefit to a specific workload it must be tested in that environment. Disclaimers aside, swapcache is appropriate for a huge variety of common workloads, the DragonFly team invites you to try it and see what a difference it can make.
Symmetric Multi-Processor Scaling (2018)
It's time to update! We ran a new set of pgbench tests on a Threadripper 2990WX (32-core/64-thread) running with 128G of ECC 2666C14 memory (8 sticks) and a power cap of 250W at the wall. The power cap was set below stock at a more maximally efficient point in the power curve. Stock power consumption usually runs in 330W range.
With the huge amount of SMP work done since 2012, the entire query path no longer has any SMP contention whatsoever and we expect a roughly linear curve until we run out of CPU cores and start digging into hyperthreads. The only possible sources of contention are increasing memory latencies as more cores load memory, and probably a certain degree of cache mastership ping-ponging that occurs even when locks are shared and do not contend. Also keep in mind that core frequencies are going the opposite direction as the CPU becomes more loaded.
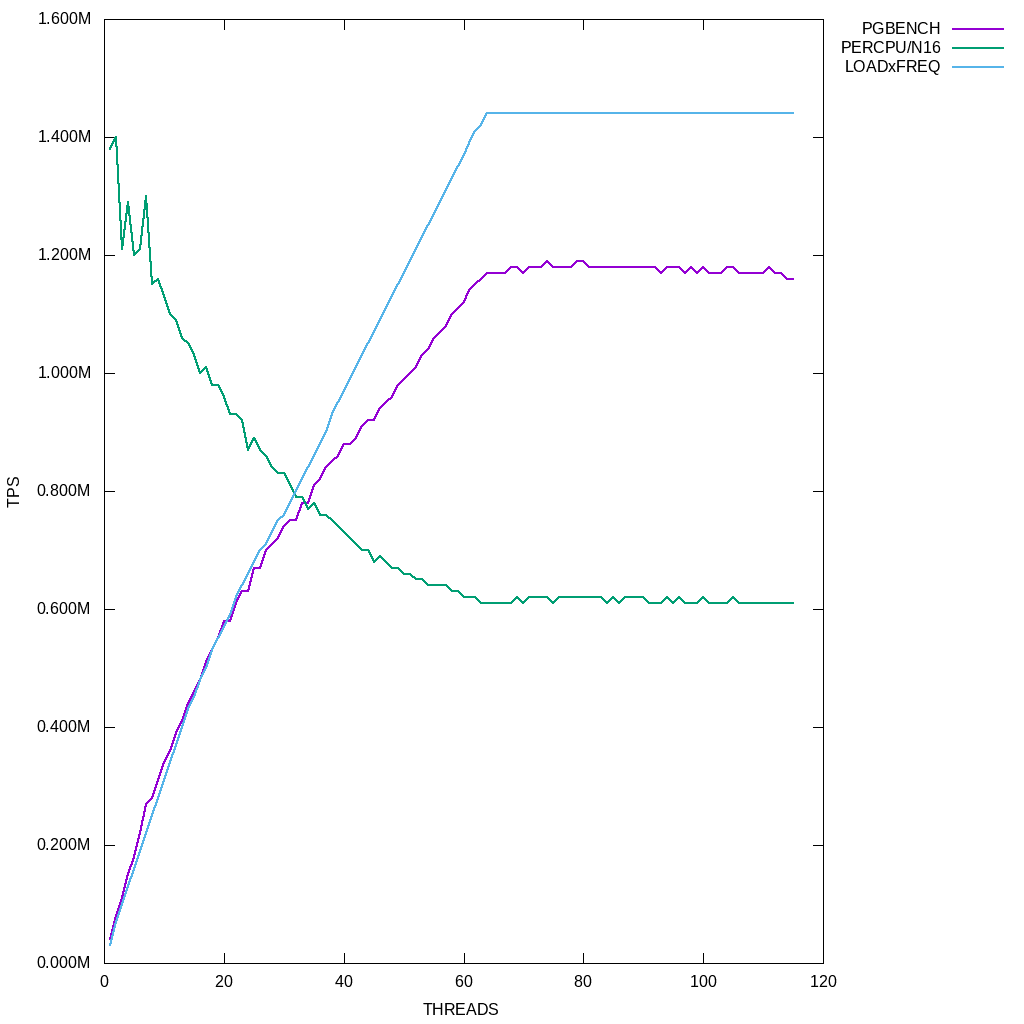
The purple curve is the actual TPS, the green curve is the measured TPS/cpu-thread (with 16 threads selected as the baseline 1.0 ratio, using the 1.0M label on the vertical scale), and the light blue curve shows the approximate cpu performance for the system (load x CPU frequency). This particular CPU was running at around 4.16 GHz with one thread, 3.73 GHz @ 16 threads, 3.12 GHz @ 32 threads, and 2.90 GHz or so at 64 threads. The horizontal thread count is the number of client processes. There is also a server process for each client process, but because the IPC is synchronous the test does not fully load all cores until just below 32 pairs. pgbench was allowed to heat-up during each run, an average of the last three 60-second samples is then graphed.
To best determine actual cpu performance, the load factor percentage is multiplied against the CPU frequency for the non-idle cores and then normalized to fit against the TPS graph. This is the light blue line on the graph. The match-up starts to diverge significantly at just below 32 clients (32 client and 32 server processes). At n=1 the load is 1.6%, at n=16 the load is 25.7%, at n=32 the load is 51%, and at 64 the load is 100% x 2.9 GHz. As you can see, the cpu continues to scale well in the 32-64 thread range, as it is digging into the hyperthreads. The reason is that in addition to the roughly 1.5x in performance you gain from hyperthreading, the hyperthreaded load is also more power efficient. The cpu frequency falls off less quickly once all 32 cores are loaded at N=32. Remember that the system under test is being capped at 250W at the wall.
From the pgbench client/server topology it is reasonable to assume that the hyperthreads really get dug into past n=32. At n=32 we had around 750K TPS and at n=64 we had 1180K TPS, 57% higher. So, roughly, hyperthreading adds around 50-60% more TPS to the results at the same power consumption. From n=32 to n=64 the cpu frequency only drops by around 7.6%. Also remember that the 4 channels of memory are probably responsible for significant stalls at these loads, meaning that the lower cpu frequency probably has less of an effect than one might think. We do not account for memory load on our blue graph. While this test is a bit wishy-washy on when hyperthreads actually start to get exercised, due to the synchronous IPC occurring between each client/server pair, the DragonFlyBSD scheduler is very, very good at its job and will use hyperthread pairs for correlated clients and servers at N=32, with one or the other idle at any given moment. This bears out in where the graph begins to diverge. Since there is no SMP contention, the divergence left over from this is likely caused by memory latency as more and more cpu threads bang on memory at the same time.